购买实例
购买实例可参考购买OpenSearch向量检索版实例。
配置集群
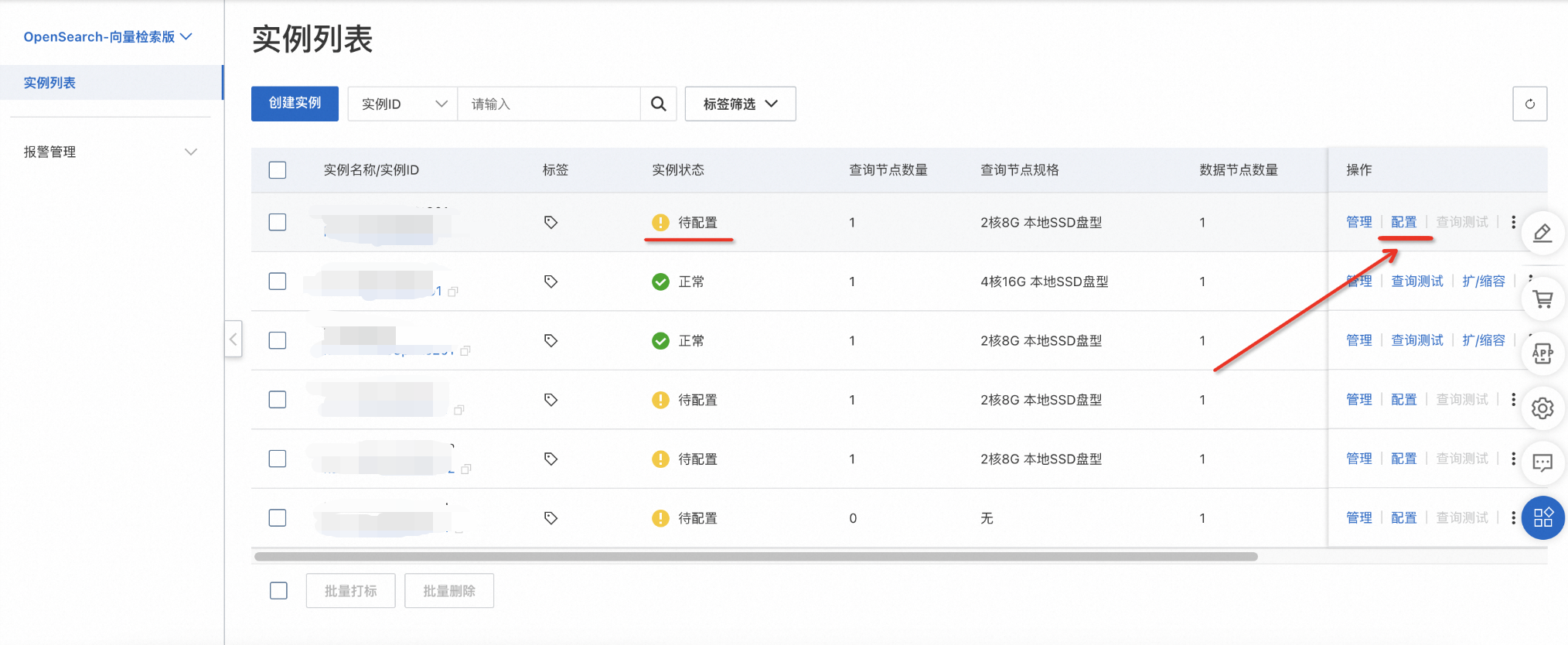
在实例列表页,新购买的实例其状态为“待配置”,之后需要点击操作栏里的配置,进入实例详情页,为实例配置表基础信息 > 数据同步 > 字段配置 > 索引结构 > 确认创建,最后等待索引重建完成即可正常搜索。
1. 表基础信息
表管理 → 添加表,进入到表基础信息页面,依次输入表名称,设置 数据分片数 和 数据更新资源数 ,场景模板选择 向量:文本语义搜索 - 稠密向量检索,确认设置信息无误后,点击下一步。
配置说明:
表名称:可自定义
数据分片数:分片数设置时,请填写不超过256的正整数, 用于提升全量构建速度、单次查询性能。(部分存量实例,仍需各索引表分片数保持一致;或至少一个索引表分片数为1,其余索引表分片数一致)
数据更新资源数:数据更新所用资源数,每个索引默认免费提供2个4核8G的更新资源,超出免费额度的资源将产生费用,详情可参考向量检索版计费概述
场景模板:向量检索版内置了3种模板可供用户选择:通用、向量-图片搜索、向量-文本语义模板
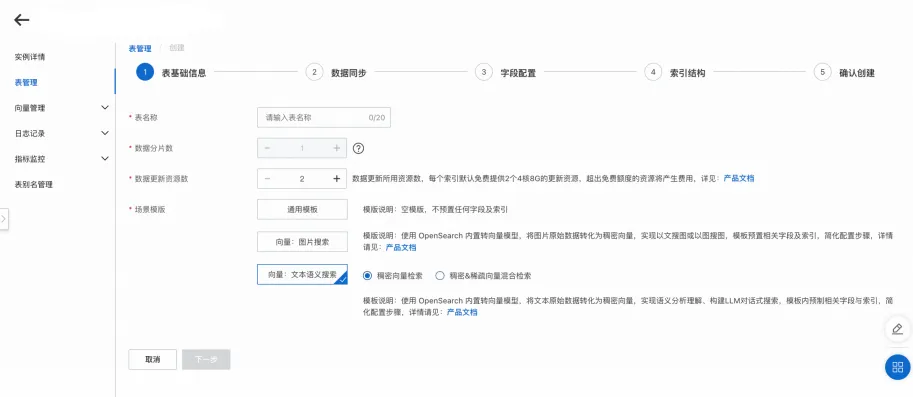
2. 数据同步
选择全量数据来源(目前支持的数据源有MaxCompute+API、对象存储OSS+API、数据湖构建(DLF)和API数据源),本文以MaxCompute+API为例,依次设置AccessKey、AccessKey Secret、Project、Table、Partition,按需选择是否开启自动索引重建,设置完成后在数据来源校验点击校验,通过后才可以进行下一步操作。
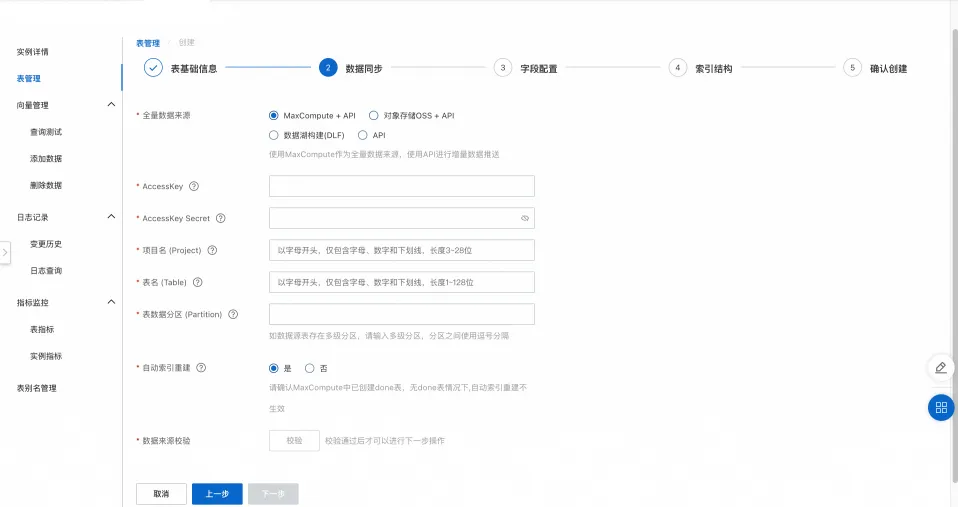
3. 字段配置
向量检索版会根据选择的场景模板,预置相关字段,并将全量数据来源中的字段,自动导入字段列表中。除了自动预设的字段外,我们还可以结合业务情况手动填写字段。
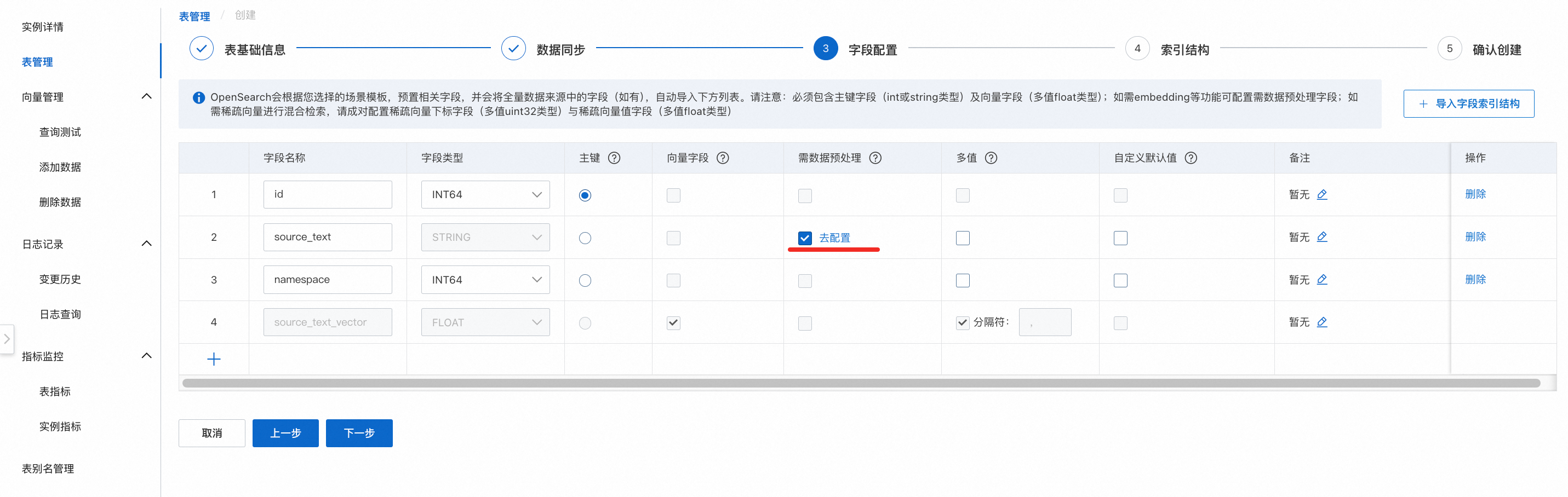
文本语义搜索模板场景的 4 个预设字段说明:
id(主键)
source_text(源文本)
namespace(命名空间)
source_text_vector、(向需要文本向量化的文本字段)
字段配置说明:
必选字段:主键字段和向量字段,主键字段为int或string类型并且需要勾选主键按钮,向量字段为float类型并且需要勾选向量字段按钮。
向量字段默认为多值的float类型,控制台建表默认采用逗号切分,支持自定义多值分隔符。
文本向量化的字段需要勾选“需embedding字段”
使用向量检索,在定义字段时有位置要求,需要按照主键字段、命名空间字段(非必要)、向量字段的顺序创建。(如上图所示)
在需数据预处理的去配置,可以对字段source_text数据预处理配置进行配置。
字段source_text数据预处理配置说明:
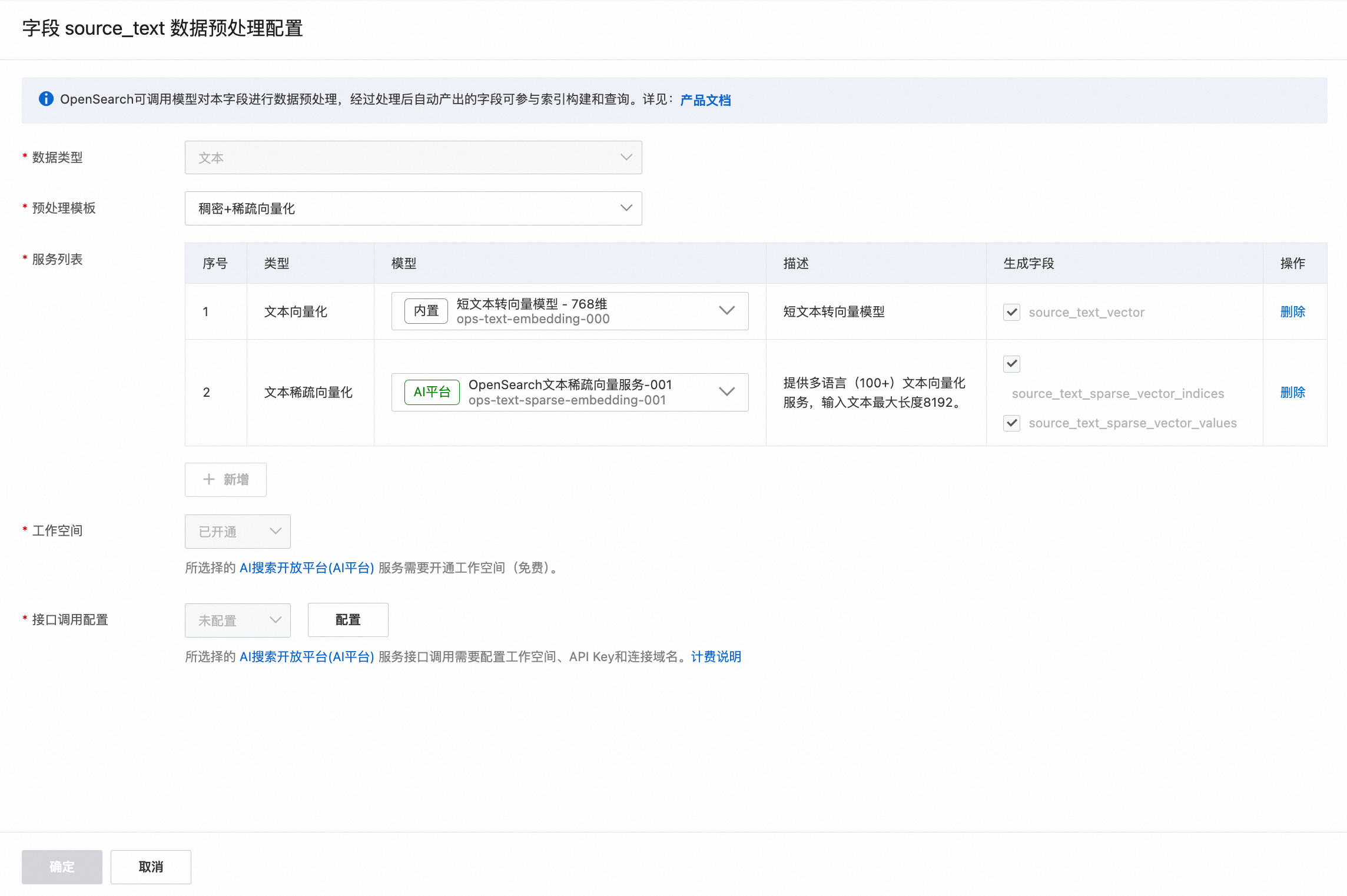
预处理模板:预处理会根据选择的场景模板,展示每种数据类型支持的模板,由于选择的是(文本语义搜索 — 稠密向量检索)场景模板,所以预处理模板展示的是稠密向量化、稠密+稀疏向量化两种。
服务列表:选定预处理模板后,自动出现模板下的服务列表。
模型:
生成字段:
embedding处理类的服务,默认生成字段,无法进行勾选或删除。
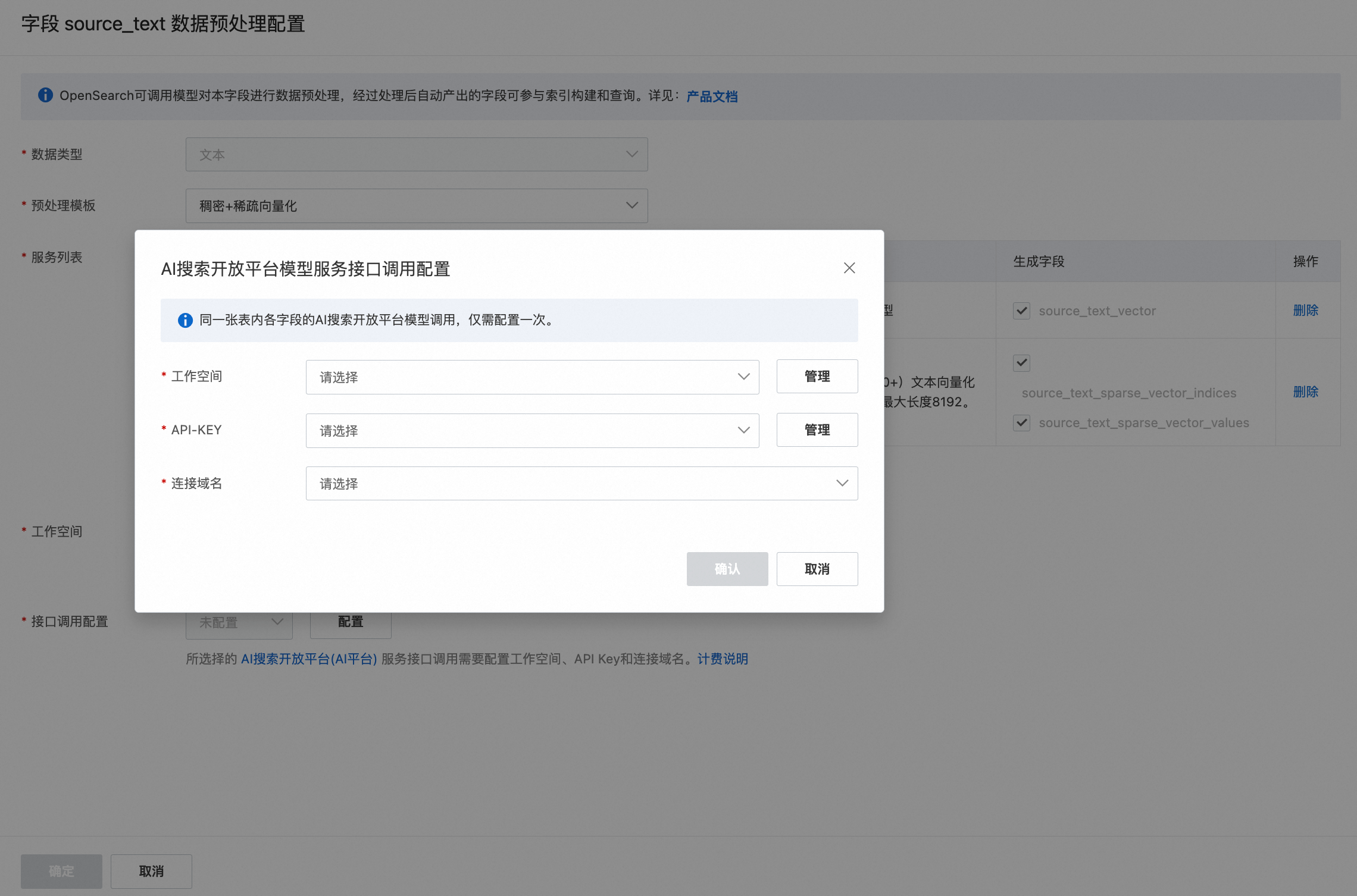
接口调用配置:由于使用了AI搜索开放平台的模型服务,所以要对服务接口调用进行配置,点击 接口调用配置 的查看配置 后,弹出 AI搜索开放平台模型服务接口调用配置 页,需要完成工作空间、API Key、连接域名 的设置。
4. 索引结构
OpenSearch会对主键与向量字段自动构建索引,索引名与字段名相同,只需要在控制台配置向量索引。
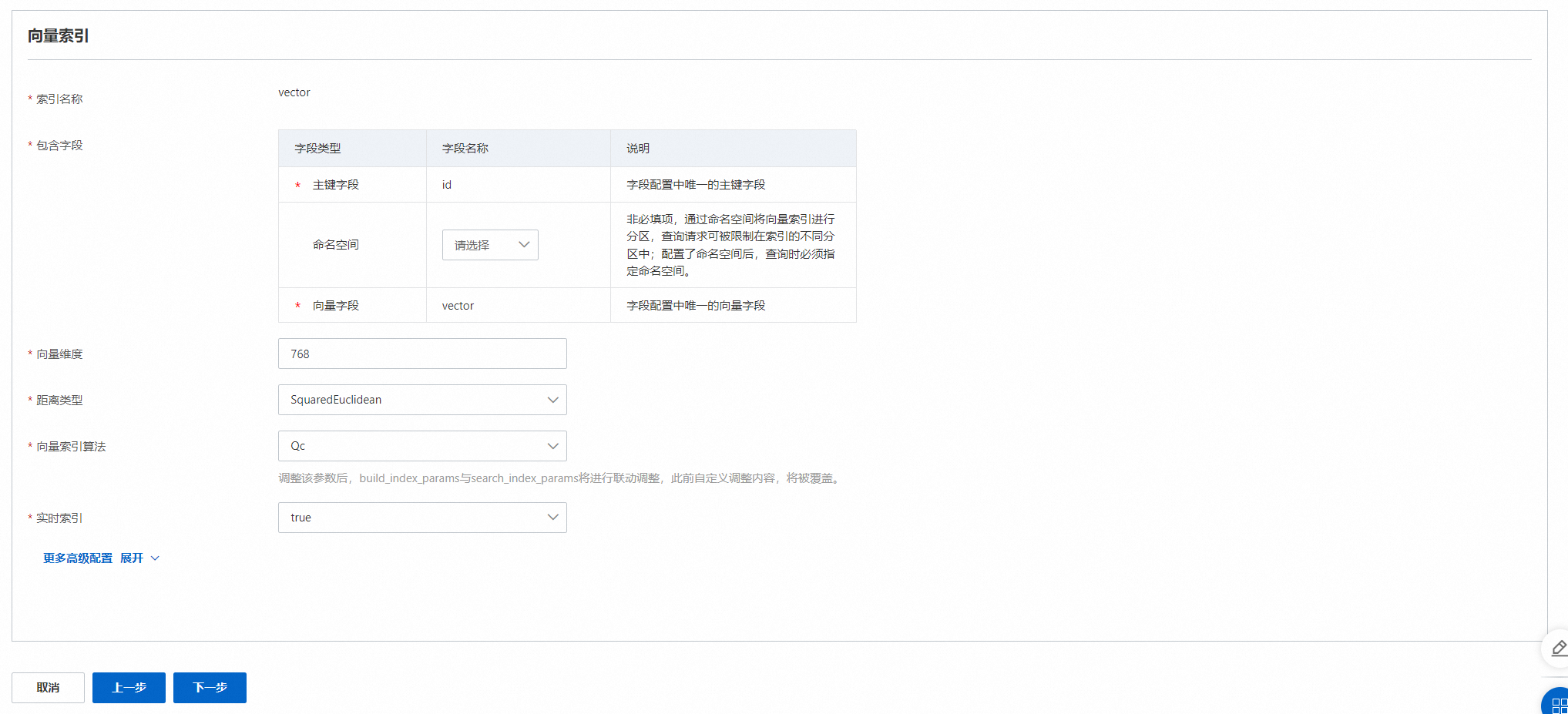
高级配置按需填写,详情可参考向量索引通用配置。
主键字段、向量字段必须填写,命名空间字段非必填,可以为空。
命名空间字段:实例引擎版本为vector service 1.0.2及以下版本,namespace标签字段不支持string格式类型;实例引擎版本为vector service 1.0.2及以上版本,无此限制。
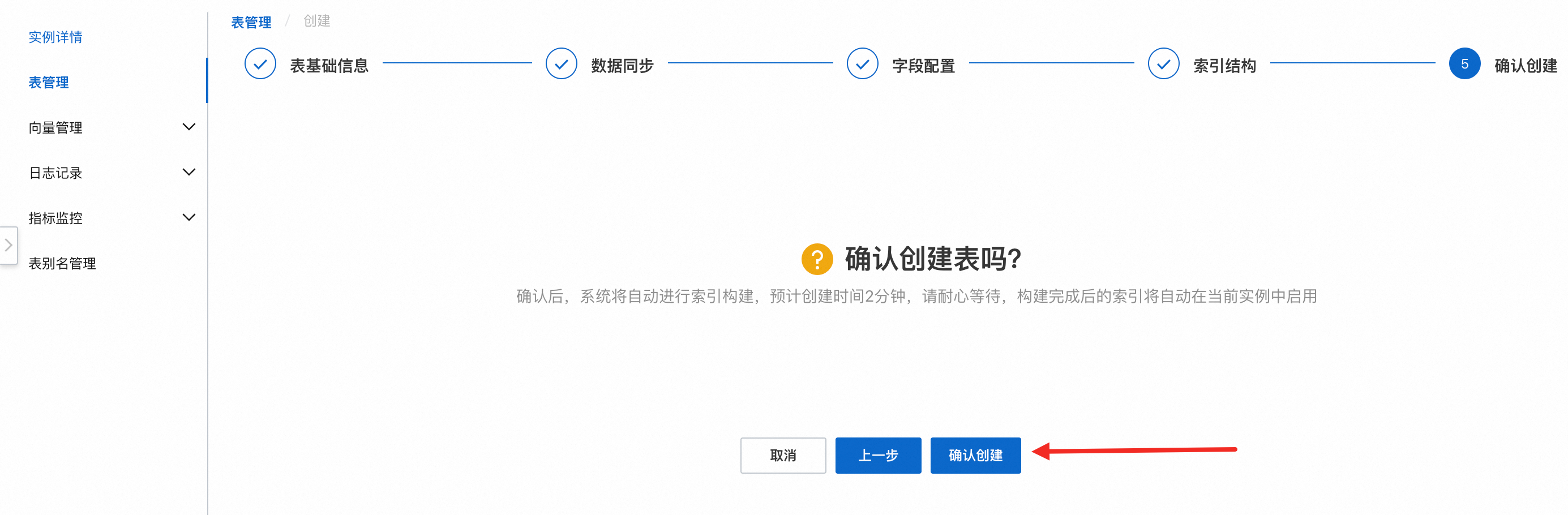
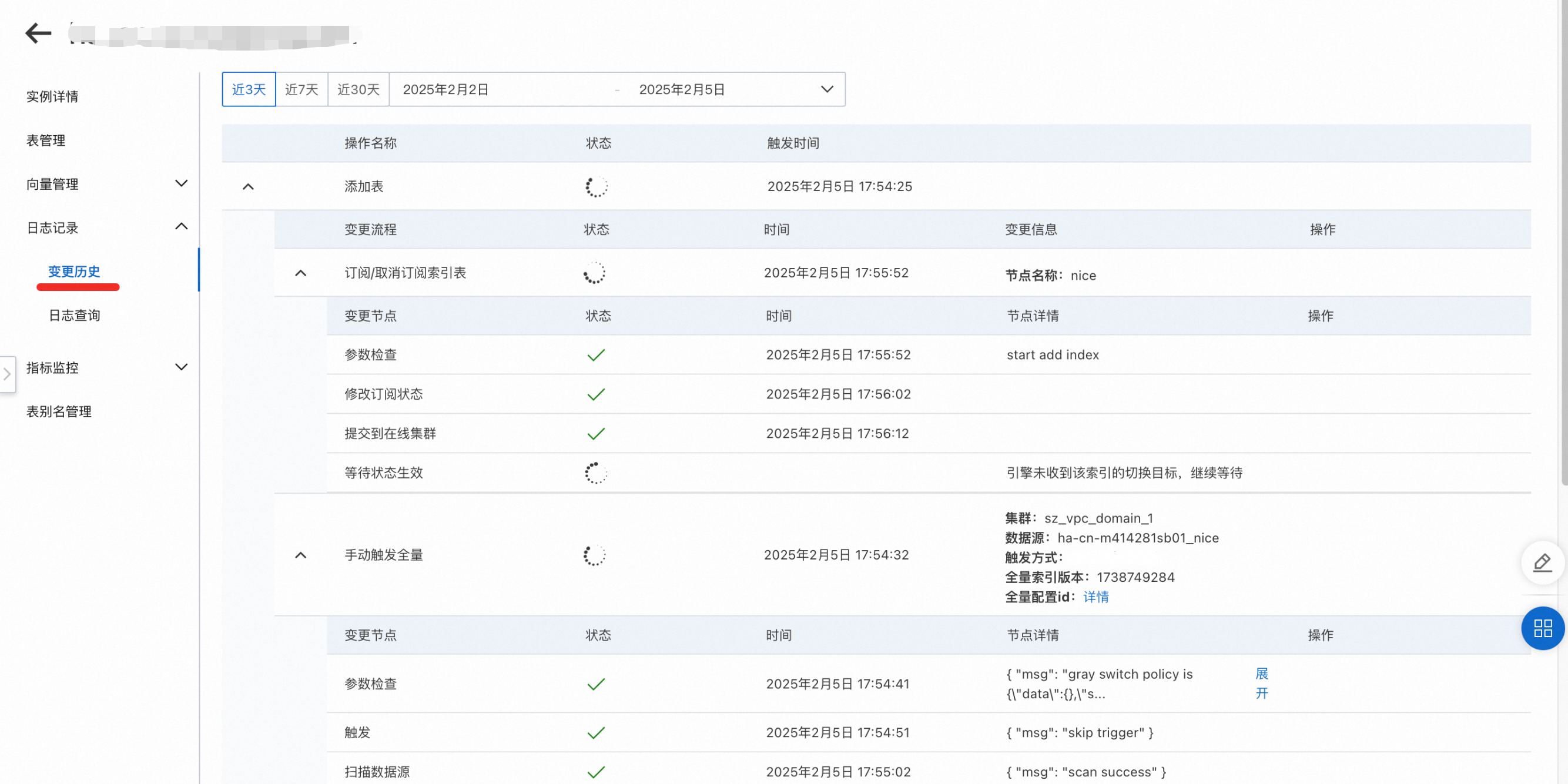
5. 确认创建
点击确认创建,完成表的创建,在左侧导航栏日志记录 > 变更历史,可以查看表的创建进度,当状态显示完成后,就可以进行查询测试的操作。
6. 查询测试
在左侧导航栏向量管理 > 查询测试进行查询,查询测试同时支持表单/开发者模式。
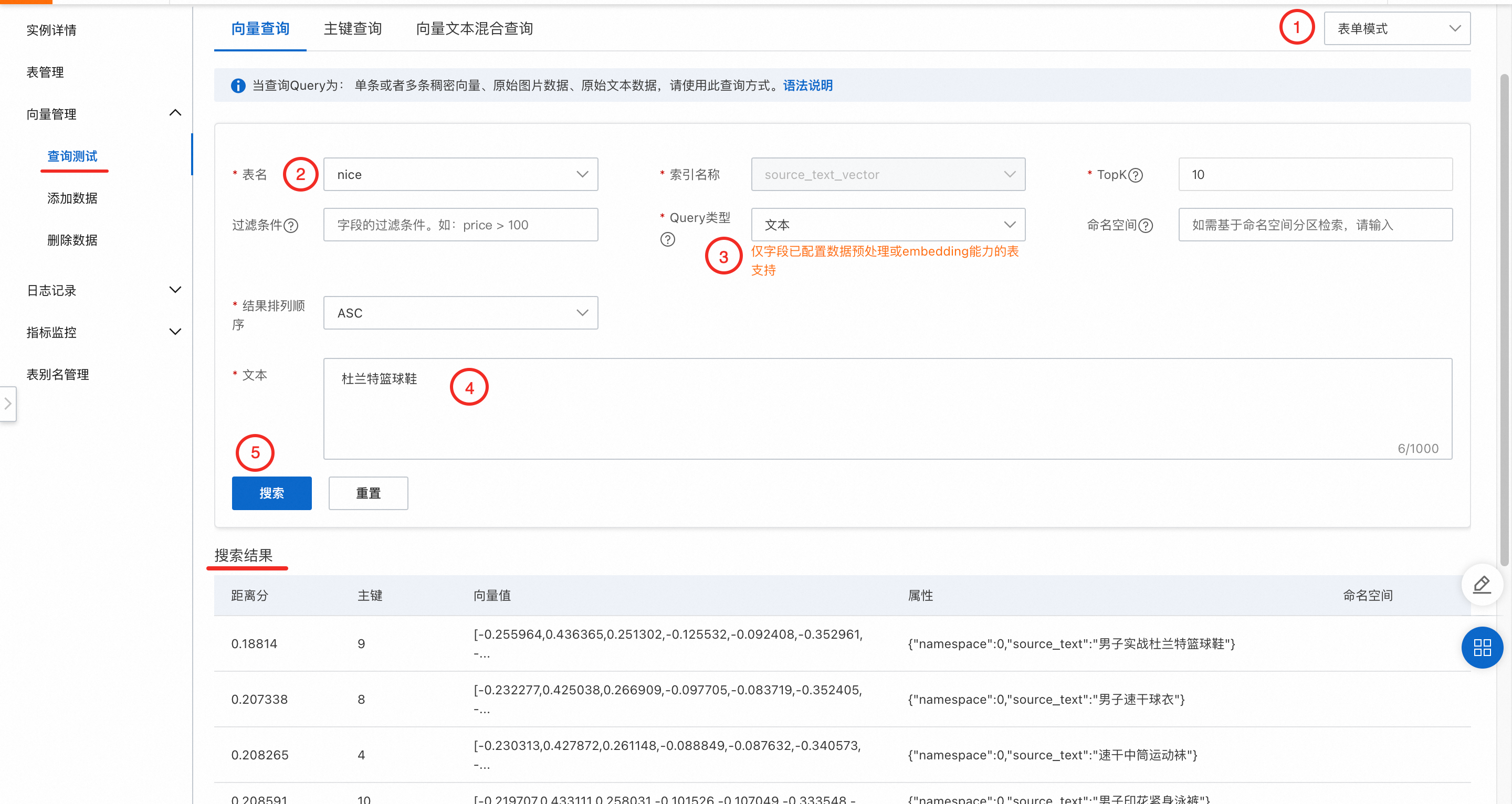
6.1 表单模式
依次选择好表单模式 > 表名,Query类型可以选择向量、文本,本次以文本类型为例,在文本项中输入查询的内容,点击搜索就可以在搜索结果栏中查看到结果了。
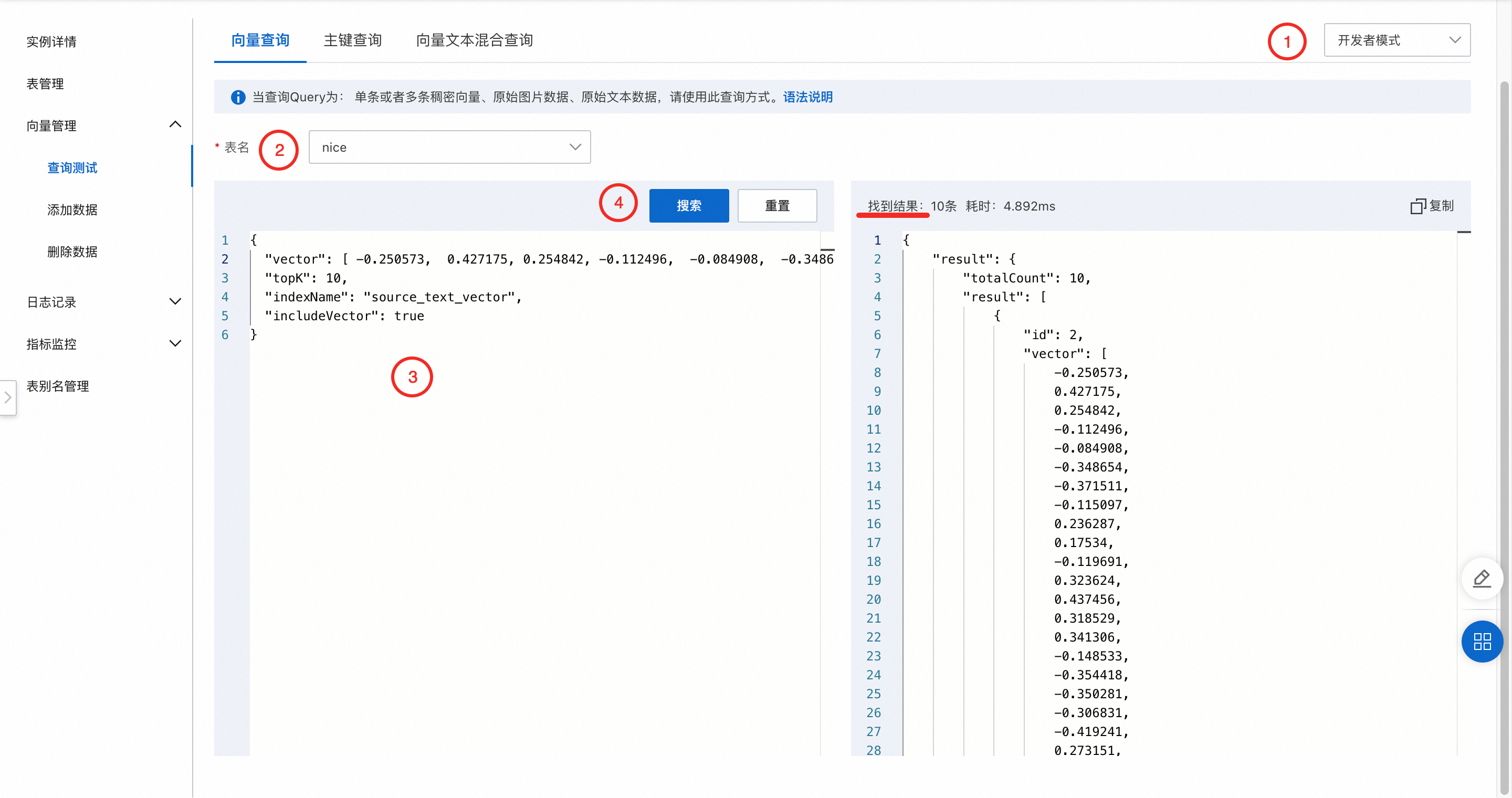
6.2 开发者模式
依次选择好开发者模式 > 表名,在下方的搜索框内输入查询参数,完成后点击搜索就可以在右侧的结果栏内看到查询结果。
详细的查询语法可参考下方的语法说明。